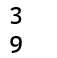recursion(재귀), 긴 함수, static, 반복문, goto 문 등을 가진 함수는 컴파일러에서 수용하지 않음
단점
인라인 함수 코드의 삽입으로 컴파일된 전체 코드 크기 증가
통계적으로 최대 30%가 증가
따라서 짧은 코드의 함수만을 인라인으로 선언하는 것이 좋음
#include<iostream>usingnamespace std;
intmain(){
int sum = 0;
for(int i=1; i<=10000; i++)
{
if((i%2)) sum += i; //인라인 함수
}
cout << sum;
}
3) 인라인 함수 vs 매크로 함수
매크로 함수
선행처리기에 의한 문자열 대치 방식
연산자 우선 순위 문제 발생
인자의 타입을 검사 X
따라서 인라인 함수를 사용하는 것이 좋
인라인 함수
컴파일러에 의한 코드 대치 방식
2. 디폴트 인자(Default Parameter)
인자에 값이 넘어오지 않는 경우, 디폴트 값을 받도록 선언된 인자
'인자 = 디폴트 값' 형태로 선언
함수의 선언부에 지정
voiddefault_sample(char c, int i, double d = 0.5 ); // 함수의 선언부에 디폴트 인자 선언voidmain(){
default_sample (‘X', 10);
default_sample (‘Y', 30, 2.0);
}
제약 조건
디폴트 인자 지정 순서
함수의 가장 오른쪽 인자부터 지정
함수 인자의 생략
함수의 가장 오른쪽 인자부터 생략
voidfoo1(char c, int i, double d);
voidfoo2(char c, int i, double d = 0.5);
voidfoo3(char c, int i = 10, double d = 0.5);
voidfoo4(char c = 'A’, int i = 10, double d = 0.5);
voidfoo(char c = 'A', int i = 10, double d = 0.5);
foo('A', 20); // 세 번째 인자만 생략함foo('B'); // 두 번째, 세 번째 인자만 생략함foo(); // 인자 모두를 생략함
디폴트 인자 예시result
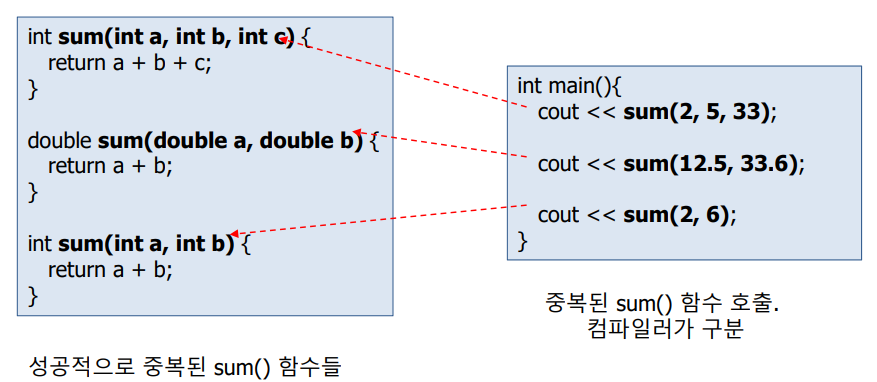
3. 함수 중복(오버로딩)
함수 오버로딩(Overloading)
이름은 같지만 인자의 개수나 데이터 형이 다른 함수를 여러 번 정의할 수 있는 기능
각각의 함수는 인자의 개수나 인자의 데이터 타입이 반드시 달라야함
함수 호출 시 전달된 인자의 데이터 타입으로 컴파일러가 어떤 함수를 호출할 지 결정
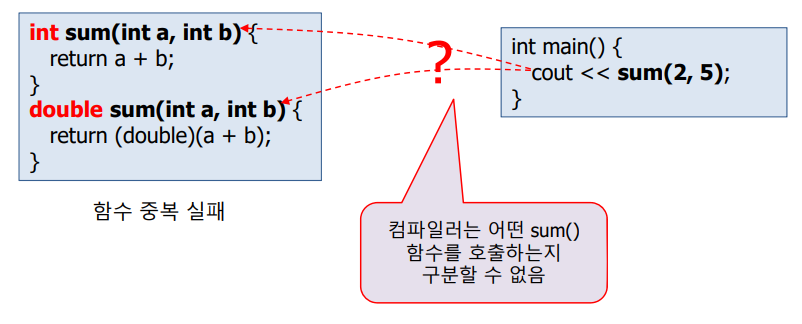
함수 중복 성공 조건
중복된 함수들의 이름 동일
중복된 함수들의 매개 변수 타입이 다르거나 개수가 달라야함
리턴 타입은 오버로딩과 무관
주의 사항 1주의 사항 2
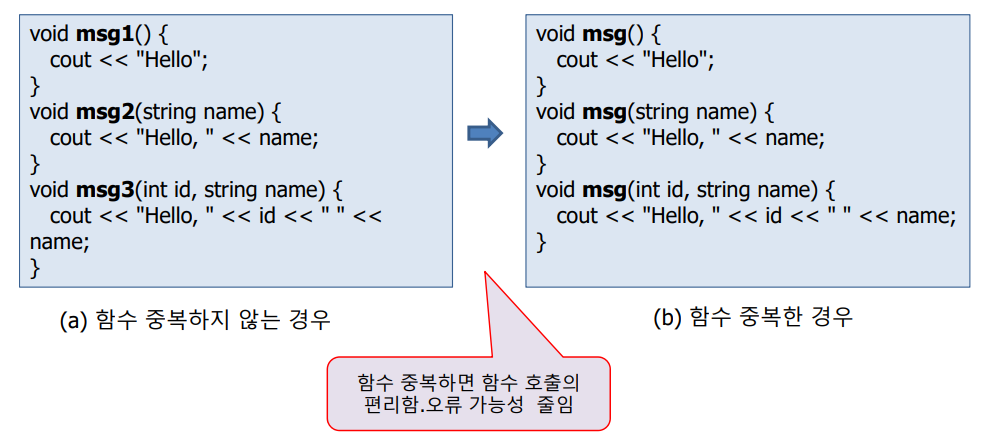
장점
함수 이름을 구분하여 기억할 필요 X
오류 가능성을 줄임
오버로딩 성공 사례오버로딩 실패 사례(리턴 타입은 무관)함수 중복의 편리성
Ex)
#include<iostream>usingnamespace std;
intbig(int a, int b){ // a와 b 중 큰 수 리턴if(a>b) return a;
elsereturn b;
}
intbig(int a[], int size){ // 배열 a[]에서 가장 큰 수 리턴int res = a[0];
for(int i=1; i<size; i++)
if(res < a[i]) res = a[i];
return res;
}
intmain(){
int array[5] = {1, 9, -2, 8, 6};
cout << big(2,3) << endl;
cout << big(array, 5) << endl;
}
result
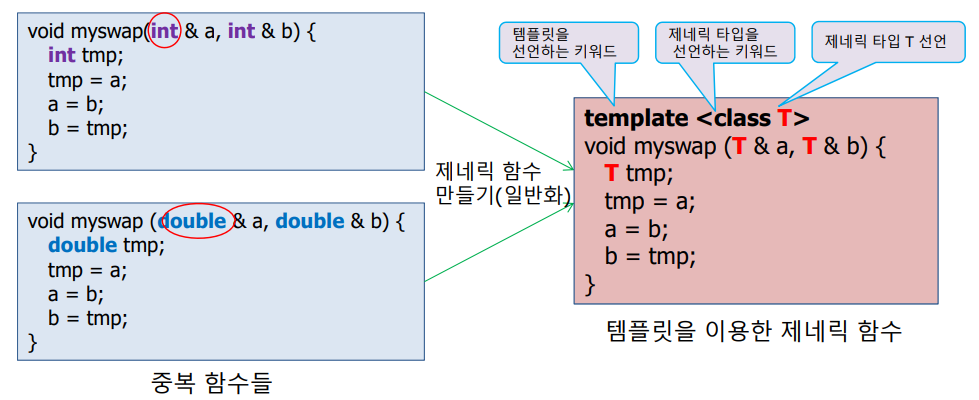
4. 함수 템플릿
1) 오버로딩의 코드 중복
만약 두 함수가 오버로딩을 통해 선언되었다면 같은 내용의 코드가 2번 선언됨
중복을 줄이기 위해 템플릿 사용
2) 일반화와 템플릿
일반화(Generic)
함수나 클래스를 일반화시키고, 매개 변수 타입을 지정하여 틀에서 찍어내듯이 함수나 클래스 코드를 생산
템플릿(Template)
함수나 클래스를 일반화하는 도구
template 키워드로 함수나 클래스 선언
변수나 매개 변수의 타입만 다르고, 코드 부분이 동일한 함수를 일반화
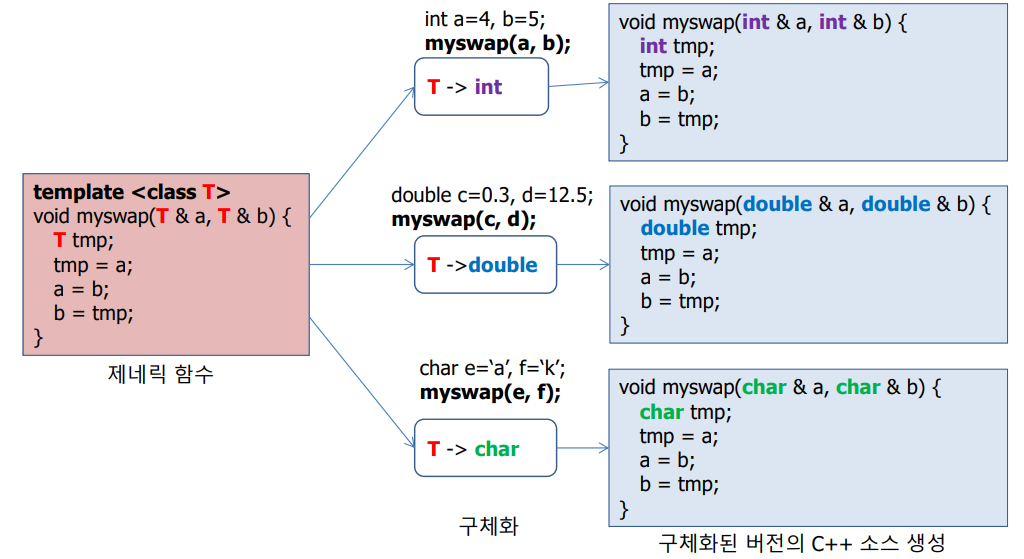
구체화(Specialization)
템플릿 함수로부터 구체화된 함수의 코드 생성
암시적 인스턴스와 명시적 인스턴스 두 가지 방
장점
함수 코드의 재사용
높은 소프트웨어 생산성과 유용성
단점
포팅에 취약
컴파일러에 따라 지원하지 않을 수 있음
컴파일 오류 메세지 빈약
디버깅에 어려움
#include<iostream>usingnamespace std;
template <classT>voidprint(T array[], int n){
cout << "템플릿" << endl;
for (int i = 0; i < n; i++)
cout << array[i] << '\t';
cout << endl;
}
voidprint(char array[], int n){ // char 배열을 출력하기 위한 함수 중복
cout << "중복함수" << endl;
for (int i = 0; i < n; i++)
cout << (int)array[i] << '\t'; // array[i]를 int 타입으로 변환하여 정수 출력
cout << endl;
}
intmain(){
int x[] = { 1,2,3,4,5 };
double d[5] = { 1.1, 2.2, 3.3, 4.4, 5.5 };
print(x, 5);
print(d, 5);
char c[5] = { 1,2,3,4,5 };
print(c, 5);
}