1. 피마 인디언 데이터 분석하기

- 샘플 수: 768
- 속성: 8
- 정보 1(pregnant): 과거 임신 횟수
- 정보 2(plasma): 포도당 부하 검사 2시간 후 공복 혈당 농도(mm Hg)
- 정보 3(pressure): 확장기 혈압(mm Hg)
- 정보 4(thickness): 삼두근 피부 주름 두께(mm)
- 정보 5(insulin): 혈청 인슐린(2-hour, mu U/ml)
- 정보 6(BMI): 체질량 지수(BMI, weight in kg/(height in m)2)
- 정보 7(pedigree): 당뇨병 가족력
- 정보 8(age): 나이
- 클래스: 2
- 0: 당뇨 아님
- 1: 당뇨
2. pandas를 활용한 데이터 조사
데이터를 다룰 때에는 라이브러리를 사용하는 것이 좋음
import pandas as pd
# 피마 인디언 당뇨병 데이터셋을 불러옵니다. 불러올 때 각 컬럼에 해당하는 이름을 지정합니다.
df = pd.read_csv('../dataset/pima-indians-diabetes.csv',
names = ["pregnant", "plasma", "pressure", "thickness", "insulin", "BMI", "pedigree", "age", "class"])
print(df.head(5))
print(df.info())
print(df.describe())
print(df[['pregnant','class']])- read_csv()
- csv 데이터 불러오기
- csv란 콤마(,)로 구분된 데이터들의 모음
- 보통의 csv파일의 경우 헤더가 있지만 예제에는 없기 때문에 names를 사용하여 속성별 키워드 지정
- csv 데이터 불러오기
- head()
- 데이터의 첫 행부터 변수 값만큼 데이터를 불러옴
- 예제에서는 5개 행 불러옴
- 불러온 데이터의 내용을 간단히 하고자 사용

- info()
- 데이터의 전반적인 정보 확인

- describe()
- 정보별 특징 확인
- 정보별 샘플 수(count)
- 평균(mean)
- 표준편차(std)
- 최솟값(min)
- 25%, 50%, 75%에 해당하는 값
- 최댓값(max)
- 정보별 특징 확인

*데이터의 일부 컬럼만 보고 싶을 때
- df [ [ '컬럼명' ] ]
- 예제는 임신횟수와 당뇨병 발병 여부 컬럼만 확인

3. 데이터 가공하기
- 단순히 데이터를 나열하는 것은 의미 X
- 따라서 데이터를 가공해야 함
print(df[['pregnant','class']].groupby(['pregnant'],as_index=False).mean().sort_values(by='pregnant',ascending=True))

- groupby( '컬럼명' )
- 컬럼명을 기준으로 하는 새 그룹 생성
- as_index=False 는 새로운 인덱스를 생성
- mean()
- 평균 구함
- sort_values()
- 컬럼명을 기준으로 오름차순
4. matplotlib를 이용해 그래프로 표현하기
- matplotlib
- 테이블을 그래프 형태로 표현하여 정확하게 파악할 수 있도록 하는 라이브러리
- seaborn
- 정교한 그래프를 그려주는 라이브러리
import matplotlib.pyplot as plt
import seaborn as sns
# 데이터 간의 상관관계를 그래프로 표현해 봅니다.
colormap = plt.cm.gist_heat #그래프의 색상 구성을 정합니다.
plt.figure(figsize=(12,12)) #그래프의 크기를 정합니다.
# 그래프의 속성을 결정합니다. vmax의 값을 0.5로 지정해 0.5에 가까울 수록 밝은 색으로 표시되게 합니다.
sns.heatmap(df.corr(),linewidths=0.1,vmax=0.5, cmap=colormap, linecolor='white', annot=True)
plt.show()- figure()
- 그래프의 크기를 결정
- heatmap()
- 두 항목씩 짝을 지은 뒤 각각 어떤 패턴으로 변화하는지를 관찰하는 함수
- 두 항목이 전혀 다른 패턴으로 변화하고 있으면 0, 서로 비슷한 패턴이라면 1에 가까운 값을 출력
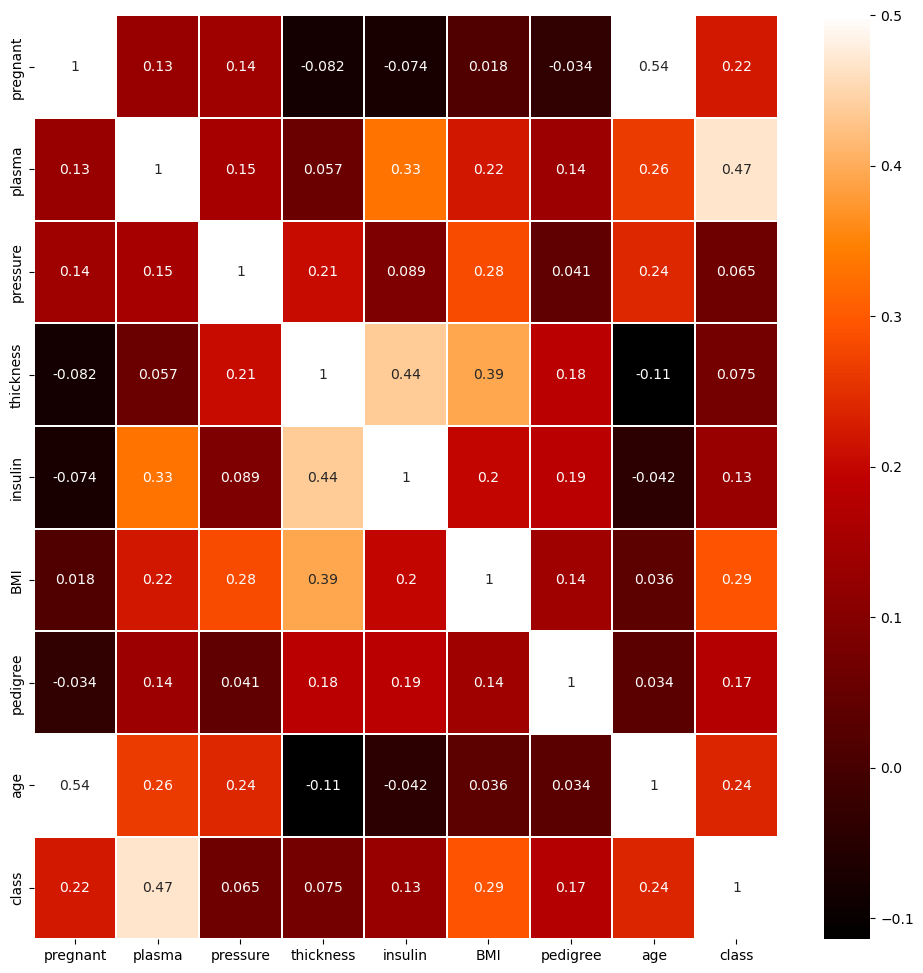
- 당뇨병 발병 여부를 가리키는 class 항목을 보면 다른 각 항목별로 상관도가 숫자로 표시되고 숫자가 높을수록 밝은 색상으로 채워짐
- 따라서 plasma 항목이 class 항목과 상관관계가 가장 높음
- 즉, plasma 항목이 결론을 만드는데 가장 중요한 역할을 한다는 것을 예측 가능함
grid = sns.FacetGrid(df, col='class')
grid.map(plt.hist, 'plasma', bins=10)
plt.show()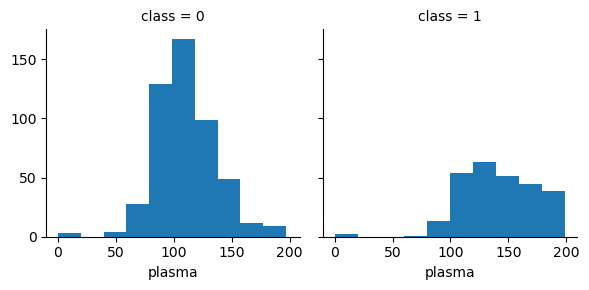
- plasma와 class항목만 따로 떼어 그래프로 확인해보면,
당뇨병 환자일수록 plasma가 150이상인 경우가 많은 것을 확인 가능
5.피마 인디언의 당뇨병 실행 예측
# 딥러닝을 구동하는 데 필요한 케라스 함수를 불러옵니다.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
# 필요한 라이브러리를 불러옵니다.
import numpy
import tensorflow as tf
# 실행할 때마다 같은 결과를 출력하기 위해 설정하는 부분입니다.
numpy.random.seed(3)
tf.random.set_seed(3)
# 데이터를 불러 옵니다.
dataset = numpy.loadtxt("C:/Users/kang mingu/pima-indians-diabetes.csv", delimiter=",")
X = dataset[:,0:8]
Y = dataset[:,8]
# 모델을 설정합니다.
model = Sequential()
model.add(Dense(12, input_dim=8, activation='relu'))
model.add(Dense(8, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
# 모델을 컴파일합니다.
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
# 모델을 실행합니다.
model.fit(X, Y, epochs=200, batch_size=10)
# 결과를 출력합니다.
print("\n Accuracy: %.4f" % (model.evaluate(X, Y)[1]))

- 약 77.08의 예측 정확도를 가짐
'ML > 모두의 딥러닝' 카테고리의 다른 글
| 13-1장) 과적합 피하기 (0) | 2023.07.11 |
|---|---|
| 12장) 다중 분류 문제 해결하기 (0) | 2023.07.11 |
| 10장) 모델 설계하기 (0) | 2023.07.10 |
| 9장) 신경망에서 딥러닝으로 (0) | 2023.07.10 |
| 8장) 오차 역전파 (0) | 2023.07.10 |